30. Packet Distributor Library
The DPDK Packet Distributor library is a library designed to be used for dynamic load balancing of traffic while supporting single packet at a time operation. When using this library, the logical cores in use are to be considered in two roles: firstly a distributor lcore, which is responsible for load balancing or distributing packets, and a set of worker lcores which are responsible for receiving the packets from the distributor and operating on them. The model of operation is shown in the diagram below.
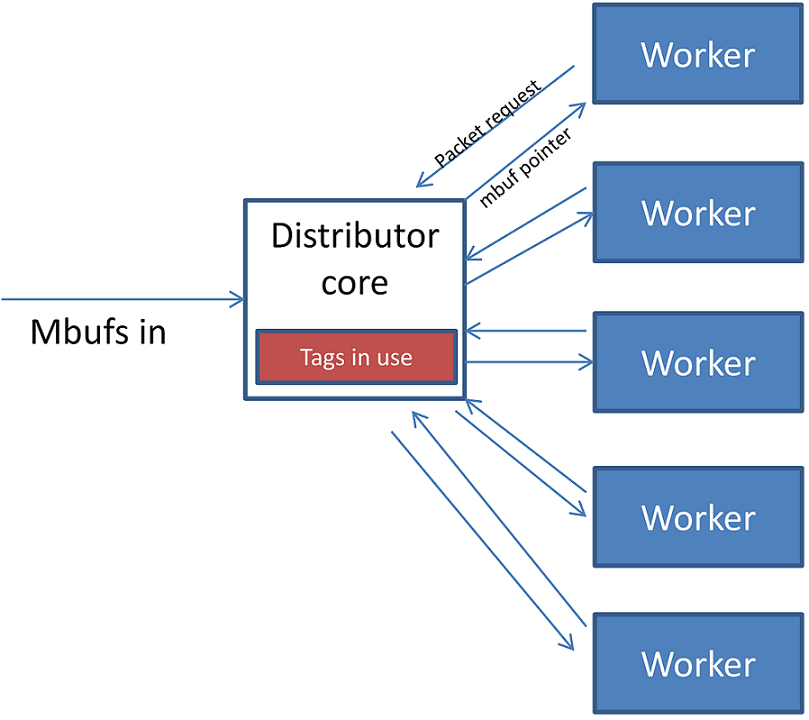
Fig. 30.2 Packet Distributor mode of operation
There are two modes of operation of the API in the distributor library,
one which sends one packet at a time to workers using 32-bits for flow_id,
and an optimized mode which sends bursts of up to 8 packets at a time to workers, using 15 bits of flow_id.
The mode is selected by the type field in the rte_distributor_create() function.
30.1. Distributor Core Operation
The distributor core does the majority of the processing for ensuring that packets are fairly shared among workers. The operation of the distributor is as follows:
- Packets are passed to the distributor component by having the distributor lcore thread call the “rte_distributor_process()” API
- The worker lcores all share a single cache line with the distributor core in order to pass messages and packets to and from the worker. The process API call will poll all the worker cache lines to see what workers are requesting packets.
- As workers request packets, the distributor takes packets from the set of packets passed in and distributes them to the workers. As it does so, it examines the “tag” – stored in the RSS hash field in the mbuf – for each packet and records what tags are being processed by each worker.
- If the next packet in the input set has a tag which is already being processed by a worker, then that packet will be queued up for processing by that worker and given to it in preference to other packets when that work next makes a request for work. This ensures that no two packets with the same tag are processed in parallel, and that all packets with the same tag are processed in input order.
- Once all input packets passed to the process API have either been distributed to workers or been queued up for a worker which is processing a given tag, then the process API returns to the caller.
Other functions which are available to the distributor lcore are:
- rte_distributor_returned_pkts()
- rte_distributor_flush()
- rte_distributor_clear_returns()
Of these the most important API call is “rte_distributor_returned_pkts()” which should only be called on the lcore which also calls the process API. It returns to the caller all packets which have finished processing by all worker cores. Within this set of returned packets, all packets sharing the same tag will be returned in their original order.
NOTE: If worker lcores buffer up packets internally for transmission in bulk afterwards, the packets sharing a tag will likely get out of order. Once a worker lcore requests a new packet, the distributor assumes that it has completely finished with the previous packet and therefore that additional packets with the same tag can safely be distributed to other workers – who may then flush their buffered packets sooner and cause packets to get out of order.
NOTE: No packet ordering guarantees are made about packets which do not share a common packet tag.
Using the process and returned_pkts API, the following application workflow can be used, while allowing packet order within a packet flow – identified by a tag – to be maintained.
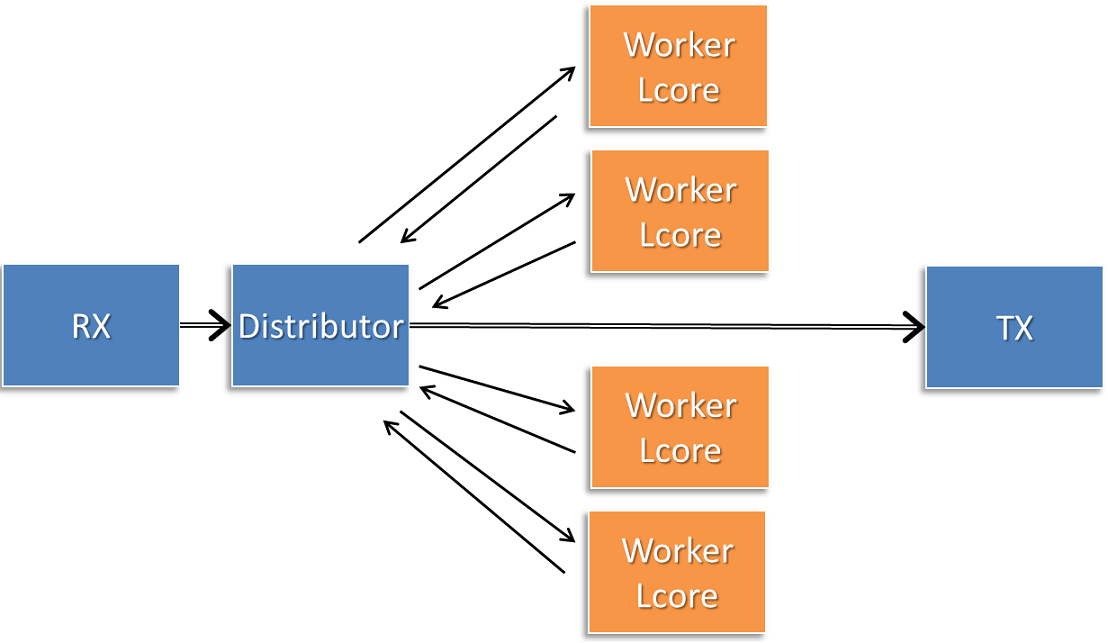
Fig. 30.3 Application workflow
The flush and clear_returns API calls, mentioned previously, are likely of less use that the process and returned_pkts APIS, and are principally provided to aid in unit testing of the library. Descriptions of these functions and their use can be found in the DPDK API Reference document.
30.2. Worker Operation
Worker cores are the cores which do the actual manipulation of the packets distributed by the packet distributor. Each worker calls “rte_distributor_get_pkt()” API to request a new packet when it has finished processing the previous one. [The previous packet should be returned to the distributor component by passing it as the final parameter to this API call.]
Since it may be desirable to vary the number of worker cores, depending on the traffic load i.e. to save power at times of lighter load, it is possible to have a worker stop processing packets by calling “rte_distributor_return_pkt()” to indicate that it has finished the current packet and does not want a new one.