8. Kernel NIC Interface Sample Application¶
The Kernel NIC Interface (KNI) is a DPDK control plane solution that allows userspace applications to exchange packets with the kernel networking stack. To accomplish this, DPDK userspace applications use an IOCTL call to request the creation of a KNI virtual device in the Linux* kernel. The IOCTL call provides interface information and the DPDK’s physical address space, which is re-mapped into the kernel address space by the KNI kernel loadable module that saves the information to a virtual device context. The DPDK creates FIFO queues for packet ingress and egress to the kernel module for each device allocated.
The KNI kernel loadable module is a standard net driver, which upon receiving the IOCTL call access the DPDK’s FIFO queue to receive/transmit packets from/to the DPDK userspace application. The FIFO queues contain pointers to data packets in the DPDK. This:
- Provides a faster mechanism to interface with the kernel net stack and eliminates system calls
- Facilitates the DPDK using standard Linux* userspace net tools (tcpdump, ftp, and so on)
- Eliminate the copy_to_user and copy_from_user operations on packets.
The Kernel NIC Interface sample application is a simple example that demonstrates the use of the DPDK to create a path for packets to go through the Linux* kernel. This is done by creating one or more kernel net devices for each of the DPDK ports. The application allows the use of standard Linux tools (ethtool, ifconfig, tcpdump) with the DPDK ports and also the exchange of packets between the DPDK application and the Linux* kernel.
8.1. Overview¶
The Kernel NIC Interface sample application uses two threads in user space for each physical NIC port being used, and allocates one or more KNI device for each physical NIC port with kernel module’s support. For a physical NIC port, one thread reads from the port and writes to KNI devices, and another thread reads from KNI devices and writes the data unmodified to the physical NIC port. It is recommended to configure one KNI device for each physical NIC port. If configured with more than one KNI devices for a physical NIC port, it is just for performance testing, or it can work together with VMDq support in future.
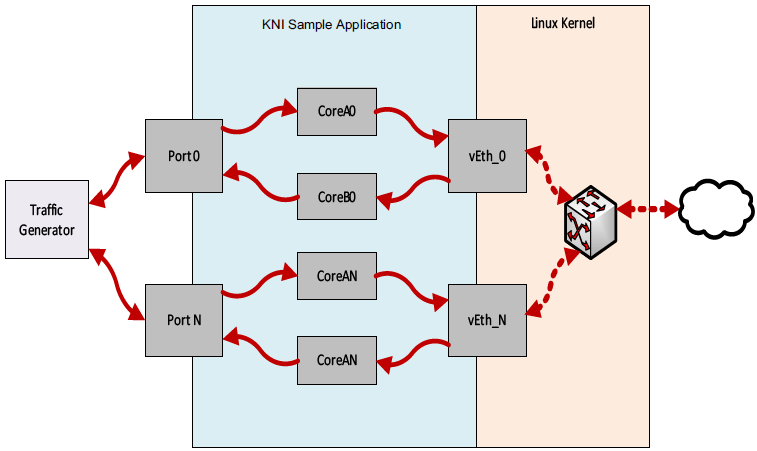
The packet flow through the Kernel NIC Interface application is as shown in the following figure.
Figure 2. Kernel NIC Application Packet Flow
8.2. Compiling the Application¶
Compile the application as follows:
Go to the example directory:
export RTE_SDK=/path/to/rte_sdk cd ${RTE_SDK}/examples/kni
Set the target (a default target is used if not specified)
Note
This application is intended as a linuxapp only.
export RTE_TARGET=x86_64-native-linuxapp-gccBuild the application:
make
8.3. Loading the Kernel Module¶
Loading the KNI kernel module without any parameter is the typical way a DPDK application gets packets into and out of the kernel net stack. This way, only one kernel thread is created for all KNI devices for packet receiving in kernel side:
#insmod rte_kni.ko
Pinning the kernel thread to a specific core can be done using a taskset command such as following:
#taskset -p 100000 `pgrep --fl kni_thread | awk '{print $1}'`
This command line tries to pin the specific kni_thread on the 20th lcore (lcore numbering starts at 0), which means it needs to check if that lcore is available on the board. This command must be sent after the application has been launched, as insmod does not start the kni thread.
For optimum performance, the lcore in the mask must be selected to be on the same socket as the lcores used in the KNI application.
To provide flexibility of performance, the kernel module of the KNI, located in the kmod sub-directory of the DPDK target directory, can be loaded with parameter of kthread_mode as follows:
#insmod rte_kni.ko kthread_mode=single
This mode will create only one kernel thread for all KNI devices for packet receiving in kernel side. By default, it is in this single kernel thread mode. It can set core affinity for this kernel thread by using Linux command taskset.
#insmod rte_kni.ko kthread_mode =multiple
This mode will create a kernel thread for each KNI device for packet receiving in kernel side. The core affinity of each kernel thread is set when creating the KNI device. The lcore ID for each kernel thread is provided in the command line of launching the application. Multiple kernel thread mode can provide scalable higher performance.
To measure the throughput in a loopback mode, the kernel module of the KNI, located in the kmod sub-directory of the DPDK target directory, can be loaded with parameters as follows:
#insmod rte_kni.ko lo_mode=lo_mode_fifo
This loopback mode will involve ring enqueue/dequeue operations in kernel space.
#insmod rte_kni.ko lo_mode=lo_mode_fifo_skb
This loopback mode will involve ring enqueue/dequeue operations and sk buffer copies in kernel space.
8.4. Running the Application¶
The application requires a number of command line options:
kni [EAL options] -- -P -p PORTMASK --config="(port,lcore_rx,lcore_tx[,lcore_kthread,...])[,port,lcore_rx,lcore_tx[,lcore_kthread,...]]"
Where:
- -P: Set all ports to promiscuous mode so that packets are accepted regardless of the packet’s Ethernet MAC destination address. Without this option, only packets with the Ethernet MAC destination address set to the Ethernet address of the port are accepted.
- -p PORTMASK: Hexadecimal bitmask of ports to configure.
- –config=”(port,lcore_rx, lcore_tx[,lcore_kthread, ...]) [, port,lcore_rx, lcore_tx[,lcore_kthread, ...]]”: Determines which lcores of RX, TX, kernel thread are mapped to which ports.
Refer to DPDK Getting Started Guide for general information on running applications and the Environment Abstraction Layer (EAL) options.
The -c coremask parameter of the EAL options should include the lcores indicated by the lcore_rx and lcore_tx, but does not need to include lcores indicated by lcore_kthread as they are used to pin the kernel thread on. The -p PORTMASK parameter should include the ports indicated by the port in –config, neither more nor less.
The lcore_kthread in –config can be configured none, one or more lcore IDs. In multiple kernel thread mode, if configured none, a KNI device will be allocated for each port, while no specific lcore affinity will be set for its kernel thread. If configured one or more lcore IDs, one or more KNI devices will be allocated for each port, while specific lcore affinity will be set for its kernel thread. In single kernel thread mode, if configured none, a KNI device will be allocated for each port. If configured one or more lcore IDs, one or more KNI devices will be allocated for each port while no lcore affinity will be set as there is only one kernel thread for all KNI devices.
For example, to run the application with two ports served by six lcores, one lcore of RX, one lcore of TX, and one lcore of kernel thread for each port:
./build/kni -c 0xf0 -n 4 -- -P -p 0x3 -config="(0,4,6,8),(1,5,7,9)"
8.5. KNI Operations¶
Once the KNI application is started, one can use different Linux* commands to manage the net interfaces. If more than one KNI devices configured for a physical port, only the first KNI device will be paired to the physical device. Operations on other KNI devices will not affect the physical port handled in user space application.
Assigning an IP address:
#ifconfig vEth0_0 192.168.0.1
Displaying the NIC registers:
#ethtool -d vEth0_0
Dumping the network traffic:
#tcpdump -i vEth0_0
When the DPDK userspace application is closed, all the KNI devices are deleted from Linux*.
8.6. Explanation¶
The following sections provide some explanation of code.
8.6.1. Initialization¶
Setup of mbuf pool, driver and queues is similar to the setup done in the L2 Forwarding sample application (see Chapter 9 “L2 Forwarding Sample Application (in Real and Virtualized Environments” for details). In addition, one or more kernel NIC interfaces are allocated for each of the configured ports according to the command line parameters.
The code for creating the kernel NIC interface for a specific port is as follows:
kni = rte_kni_create(port, MAX_PACKET_SZ, pktmbuf_pool, &kni_ops);
if (kni == NULL)
rte_exit(EXIT_FAILURE, "Fail to create kni dev "
"for port: %d\n", port);
The code for allocating the kernel NIC interfaces for a specific port is as follows:
static int
kni_alloc(uint8_t port_id)
{
uint8_t i;
struct rte_kni *kni;
struct rte_kni_conf conf;
struct kni_port_params **params = kni_port_params_array;
if (port_id >= RTE_MAX_ETHPORTS || !params[port_id])
return -1;
params[port_id]->nb_kni = params[port_id]->nb_lcore_k ? params[port_id]->nb_lcore_k : 1;
for (i = 0; i < params[port_id]->nb_kni; i++) {
/* Clear conf at first */
memset(&conf, 0, sizeof(conf));
if (params[port_id]->nb_lcore_k) {
rte_snprintf(conf.name, RTE_KNI_NAMESIZE, "vEth%u_%u", port_id, i);
conf.core_id = params[port_id]->lcore_k[i];
conf.force_bind = 1;
} else
rte_snprintf(conf.name, RTE_KNI_NAMESIZE, "vEth%u", port_id);
conf.group_id = (uint16_t)port_id;
conf.mbuf_size = MAX_PACKET_SZ;
/*
* The first KNI device associated to a port
* is the master, for multiple kernel thread
* environment.
*/
if (i == 0) {
struct rte_kni_ops ops;
struct rte_eth_dev_info dev_info;
memset(&dev_info, 0, sizeof(dev_info)); rte_eth_dev_info_get(port_id, &dev_info);
conf.addr = dev_info.pci_dev->addr;
conf.id = dev_info.pci_dev->id;
memset(&ops, 0, sizeof(ops));
ops.port_id = port_id;
ops.change_mtu = kni_change_mtu;
ops.config_network_if = kni_config_network_interface;
kni = rte_kni_alloc(pktmbuf_pool, &conf, &ops);
} else
kni = rte_kni_alloc(pktmbuf_pool, &conf, NULL);
if (!kni)
rte_exit(EXIT_FAILURE, "Fail to create kni for "
"port: %d\n", port_id);
params[port_id]->kni[i] = kni;
}
return 0;
}
The other step in the initialization process that is unique to this sample application is the association of each port with lcores for RX, TX and kernel threads.
- One lcore to read from the port and write to the associated one or more KNI devices
- Another lcore to read from one or more KNI devices and write to the port
- Other lcores for pinning the kernel threads on one by one
This is done by using the`kni_port_params_array[]` array, which is indexed by the port ID. The code is as follows:
static int
parse_config(const char *arg)
{
const char *p, *p0 = arg;
char s[256], *end;
unsigned size;
enum fieldnames {
FLD_PORT = 0,
FLD_LCORE_RX,
FLD_LCORE_TX,
_NUM_FLD = KNI_MAX_KTHREAD + 3,
};
int i, j, nb_token;
char *str_fld[_NUM_FLD];
unsigned long int_fld[_NUM_FLD];
uint8_t port_id, nb_kni_port_params = 0;
memset(&kni_port_params_array, 0, sizeof(kni_port_params_array));
while (((p = strchr(p0, '(')) != NULL) && nb_kni_port_params < RTE_MAX_ETHPORTS) {
p++;
if ((p0 = strchr(p, ')')) == NULL)
goto fail;
size = p0 - p;
if (size >= sizeof(s)) {
printf("Invalid config parameters\n");
goto fail;
}
rte_snprintf(s, sizeof(s), "%.*s", size, p);
nb_token = rte_strsplit(s, sizeof(s), str_fld, _NUM_FLD, ',');
if (nb_token <= FLD_LCORE_TX) {
printf("Invalid config parameters\n");
goto fail;
}
for (i = 0; i < nb_token; i++) {
errno = 0;
int_fld[i] = strtoul(str_fld[i], &end, 0);
if (errno != 0 || end == str_fld[i]) {
printf("Invalid config parameters\n");
goto fail;
}
}
i = 0;
port_id = (uint8_t)int_fld[i++];
if (port_id >= RTE_MAX_ETHPORTS) {
printf("Port ID %u could not exceed the maximum %u\n", port_id, RTE_MAX_ETHPORTS);
goto fail;
}
if (kni_port_params_array[port_id]) {
printf("Port %u has been configured\n", port_id);
goto fail;
}
kni_port_params_array[port_id] = (struct kni_port_params*)rte_zmalloc("KNI_port_params", sizeof(struct kni_port_params), RTE_CACHE_LINE_SIZE);
kni_port_params_array[port_id]->port_id = port_id;
kni_port_params_array[port_id]->lcore_rx = (uint8_t)int_fld[i++];
kni_port_params_array[port_id]->lcore_tx = (uint8_t)int_fld[i++];
if (kni_port_params_array[port_id]->lcore_rx >= RTE_MAX_LCORE || kni_port_params_array[port_id]->lcore_tx >= RTE_MAX_LCORE) {
printf("lcore_rx %u or lcore_tx %u ID could not "
"exceed the maximum %u\n",
kni_port_params_array[port_id]->lcore_rx, kni_port_params_array[port_id]->lcore_tx, RTE_MAX_LCORE);
goto fail;
}
for (j = 0; i < nb_token && j < KNI_MAX_KTHREAD; i++, j++)
kni_port_params_array[port_id]->lcore_k[j] = (uint8_t)int_fld[i];
kni_port_params_array[port_id]->nb_lcore_k = j;
}
print_config();
return 0;
fail:
for (i = 0; i < RTE_MAX_ETHPORTS; i++) {
if (kni_port_params_array[i]) {
rte_free(kni_port_params_array[i]);
kni_port_params_array[i] = NULL;
}
}
return -1;
}
8.6.2. Packet Forwarding¶
After the initialization steps are completed, the main_loop() function is run on each lcore. This function first checks the lcore_id against the user provided lcore_rx and lcore_tx to see if this lcore is reading from or writing to kernel NIC interfaces.
For the case that reads from a NIC port and writes to the kernel NIC interfaces, the packet reception is the same as in L2 Forwarding sample application (see Section 9.4.6 “Receive, Process and Transmit Packets”). The packet transmission is done by sending mbufs into the kernel NIC interfaces by rte_kni_tx_burst(). The KNI library automatically frees the mbufs after the kernel successfully copied the mbufs.
/**
* Interface to burst rx and enqueue mbufs into rx_q
*/
static void
kni_ingress(struct kni_port_params *p)
{
uint8_t i, nb_kni, port_id;
unsigned nb_rx, num;
struct rte_mbuf *pkts_burst[PKT_BURST_SZ];
if (p == NULL)
return;
nb_kni = p->nb_kni;
port_id = p->port_id;
for (i = 0; i < nb_kni; i++) {
/* Burst rx from eth */
nb_rx = rte_eth_rx_burst(port_id, 0, pkts_burst, PKT_BURST_SZ);
if (unlikely(nb_rx > PKT_BURST_SZ)) {
RTE_LOG(ERR, APP, "Error receiving from eth\n");
return;
}
/* Burst tx to kni */
num = rte_kni_tx_burst(p->kni[i], pkts_burst, nb_rx);
kni_stats[port_id].rx_packets += num;
rte_kni_handle_request(p->kni[i]);
if (unlikely(num < nb_rx)) {
/* Free mbufs not tx to kni interface */
kni_burst_free_mbufs(&pkts_burst[num], nb_rx - num);
kni_stats[port_id].rx_dropped += nb_rx - num;
}
}
}
For the other case that reads from kernel NIC interfaces and writes to a physical NIC port, packets are retrieved by reading mbufs from kernel NIC interfaces by rte_kni_rx_burst(). The packet transmission is the same as in the L2 Forwarding sample application (see Section 9.4.6 “Receive, Process and Transmit Packet’s”).
/**
* Interface to dequeue mbufs from tx_q and burst tx
*/
static void
kni_egress(struct kni_port_params *p)
{
uint8_t i, nb_kni, port_id;
unsigned nb_tx, num;
struct rte_mbuf *pkts_burst[PKT_BURST_SZ];
if (p == NULL)
return;
nb_kni = p->nb_kni;
port_id = p->port_id;
for (i = 0; i < nb_kni; i++) {
/* Burst rx from kni */
num = rte_kni_rx_burst(p->kni[i], pkts_burst, PKT_BURST_SZ);
if (unlikely(num > PKT_BURST_SZ)) {
RTE_LOG(ERR, APP, "Error receiving from KNI\n");
return;
}
/* Burst tx to eth */
nb_tx = rte_eth_tx_burst(port_id, 0, pkts_burst, (uint16_t)num);
kni_stats[port_id].tx_packets += nb_tx;
if (unlikely(nb_tx < num)) {
/* Free mbufs not tx to NIC */
kni_burst_free_mbufs(&pkts_burst[nb_tx], num - nb_tx);
kni_stats[port_id].tx_dropped += num - nb_tx;
}
}
}
8.6.3. Callbacks for Kernel Requests¶
To execute specific PMD operations in user space requested by some Linux* commands, callbacks must be implemented and filled in the struct rte_kni_ops structure. Currently, setting a new MTU and configuring the network interface (up/ down) are supported.
static struct rte_kni_ops kni_ops = {
.change_mtu = kni_change_mtu,
.config_network_if = kni_config_network_interface,
};
/* Callback for request of changing MTU */
static int
kni_change_mtu(uint8_t port_id, unsigned new_mtu)
{
int ret;
struct rte_eth_conf conf;
if (port_id >= rte_eth_dev_count()) {
RTE_LOG(ERR, APP, "Invalid port id %d\n", port_id);
return -EINVAL;
}
RTE_LOG(INFO, APP, "Change MTU of port %d to %u\n", port_id, new_mtu);
/* Stop specific port */
rte_eth_dev_stop(port_id);
memcpy(&conf, &port_conf, sizeof(conf));
/* Set new MTU */
if (new_mtu > ETHER_MAX_LEN)
conf.rxmode.jumbo_frame = 1;
else
conf.rxmode.jumbo_frame = 0;
/* mtu + length of header + length of FCS = max pkt length */
conf.rxmode.max_rx_pkt_len = new_mtu + KNI_ENET_HEADER_SIZE + KNI_ENET_FCS_SIZE;
ret = rte_eth_dev_configure(port_id, 1, 1, &conf);
if (ret < 0) {
RTE_LOG(ERR, APP, "Fail to reconfigure port %d\n", port_id);
return ret;
}
/* Restart specific port */
ret = rte_eth_dev_start(port_id);
if (ret < 0) {
RTE_LOG(ERR, APP, "Fail to restart port %d\n", port_id);
return ret;
}
return 0;
}
/* Callback for request of configuring network interface up/down */
static int
kni_config_network_interface(uint8_t port_id, uint8_t if_up)
{
int ret = 0;
if (port_id >= rte_eth_dev_count() || port_id >= RTE_MAX_ETHPORTS) {
RTE_LOG(ERR, APP, "Invalid port id %d\n", port_id);
return -EINVAL;
}
RTE_LOG(INFO, APP, "Configure network interface of %d %s\n",
port_id, if_up ? "up" : "down");
if (if_up != 0) {
/* Configure network interface up */
rte_eth_dev_stop(port_id);
ret = rte_eth_dev_start(port_id);
} else /* Configure network interface down */
rte_eth_dev_stop(port_id);
if (ret < 0)
RTE_LOG(ERR, APP, "Failed to start port %d\n", port_id);
return ret;
}