18. Kernel NIC Interface¶
The DPDK Kernel NIC Interface (KNI) allows userspace applications access to the Linux* control plane.
The benefits of using the DPDK KNI are:
- Faster than existing Linux TUN/TAP interfaces (by eliminating system calls and copy_to_user()/copy_from_user() operations.
- Allows management of DPDK ports using standard Linux net tools such as ethtool, ifconfig and tcpdump.
- Allows an interface with the kernel network stack.
The components of an application using the DPDK Kernel NIC Interface are shown in Fig. 18.1.
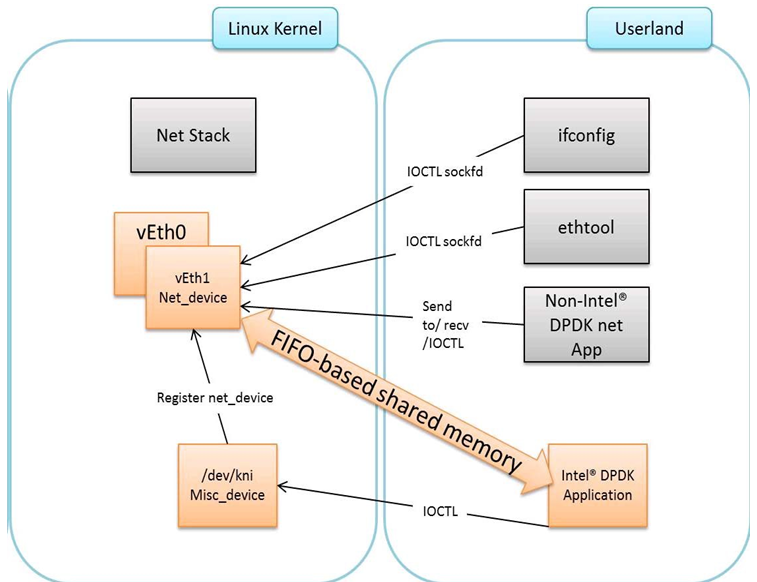
Fig. 18.1 Components of a DPDK KNI Application
18.1. The DPDK KNI Kernel Module¶
The KNI kernel loadable module provides support for two types of devices:
- A Miscellaneous device (/dev/kni) that:
- Creates net devices (via ioctl calls).
- Maintains a kernel thread context shared by all KNI instances (simulating the RX side of the net driver).
- For single kernel thread mode, maintains a kernel thread context shared by all KNI instances (simulating the RX side of the net driver).
- For multiple kernel thread mode, maintains a kernel thread context for each KNI instance (simulating the RX side of the new driver).
- Net device:
- Net functionality provided by implementing several operations such as netdev_ops, header_ops, ethtool_ops that are defined by struct net_device, including support for DPDK mbufs and FIFOs.
- The interface name is provided from userspace.
- The MAC address can be the real NIC MAC address or random.
18.2. KNI Creation and Deletion¶
The KNI interfaces are created by a DPDK application dynamically. The interface name and FIFO details are provided by the application through an ioctl call using the rte_kni_device_info struct which contains:
- The interface name.
- Physical addresses of the corresponding memzones for the relevant FIFOs.
- Mbuf mempool details, both physical and virtual (to calculate the offset for mbuf pointers).
- PCI information.
- Core affinity.
Refer to rte_kni_common.h in the DPDK source code for more details.
The physical addresses will be re-mapped into the kernel address space and stored in separate KNI contexts.
Once KNI interfaces are created, the KNI context information can be queried by calling the rte_kni_info_get() function.
The KNI interfaces can be deleted by a DPDK application dynamically after being created. Furthermore, all those KNI interfaces not deleted will be deleted on the release operation of the miscellaneous device (when the DPDK application is closed).
18.3. DPDK mbuf Flow¶
To minimize the amount of DPDK code running in kernel space, the mbuf mempool is managed in userspace only. The kernel module will be aware of mbufs, but all mbuf allocation and free operations will be handled by the DPDK application only.
Fig. 18.2 shows a typical scenario with packets sent in both directions.
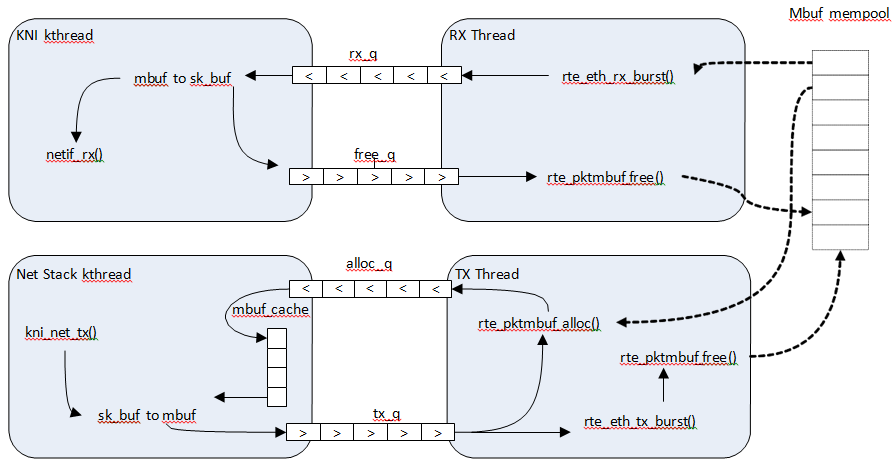
Fig. 18.2 Packet Flow via mbufs in the DPDK KNI
18.4. Use Case: Ingress¶
On the DPDK RX side, the mbuf is allocated by the PMD in the RX thread context. This thread will enqueue the mbuf in the rx_q FIFO. The KNI thread will poll all KNI active devices for the rx_q. If an mbuf is dequeued, it will be converted to a sk_buff and sent to the net stack via netif_rx(). The dequeued mbuf must be freed, so the same pointer is sent back in the free_q FIFO.
The RX thread, in the same main loop, polls this FIFO and frees the mbuf after dequeuing it.
18.5. Use Case: Egress¶
For packet egress the DPDK application must first enqueue several mbufs to create an mbuf cache on the kernel side.
The packet is received from the Linux net stack, by calling the kni_net_tx() callback. The mbuf is dequeued (without waiting due the cache) and filled with data from sk_buff. The sk_buff is then freed and the mbuf sent in the tx_q FIFO.
The DPDK TX thread dequeues the mbuf and sends it to the PMD (via rte_eth_tx_burst()). It then puts the mbuf back in the cache.
18.6. Ethtool¶
Ethtool is a Linux-specific tool with corresponding support in the kernel where each net device must register its own callbacks for the supported operations. The current implementation uses the igb/ixgbe modified Linux drivers for ethtool support. Ethtool is not supported in i40e and VMs (VF or EM devices).
18.7. Link state and MTU change¶
Link state and MTU change are network interface specific operations usually done via ifconfig. The request is initiated from the kernel side (in the context of the ifconfig process) and handled by the user space DPDK application. The application polls the request, calls the application handler and returns the response back into the kernel space.
The application handlers can be registered upon interface creation or explicitly registered/unregistered in runtime. This provides flexibility in multiprocess scenarios (where the KNI is created in the primary process but the callbacks are handled in the secondary one). The constraint is that a single process can register and handle the requests.
18.8. KNI Working as a Kernel vHost Backend¶
vHost is a kernel module usually working as the backend of virtio (a para- virtualization driver framework) to accelerate the traffic from the guest to the host. The DPDK Kernel NIC interface provides the ability to hookup vHost traffic into userspace DPDK application. Together with the DPDK PMD virtio, it significantly improves the throughput between guest and host. In the scenario where DPDK is running as fast path in the host, kni-vhost is an efficient path for the traffic.
18.8.1. Overview¶
vHost-net has three kinds of real backend implementations. They are: 1) tap, 2) macvtap and 3) RAW socket. The main idea behind kni-vhost is making the KNI work as a RAW socket, attaching it as the backend instance of vHost-net. It is using the existing interface with vHost-net, so it does not require any kernel hacking, and is fully-compatible with the kernel vhost module. As vHost is still taking responsibility for communicating with the front-end virtio, it naturally supports both legacy virtio -net and the DPDK PMD virtio. There is a little penalty that comes from the non-polling mode of vhost. However, it scales throughput well when using KNI in multi-thread mode.
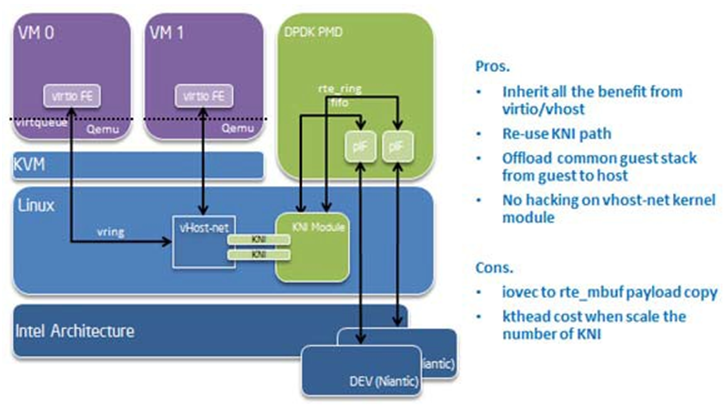
Fig. 18.3 vHost-net Architecture Overview
18.8.2. Packet Flow¶
There is only a minor difference from the original KNI traffic flows. On transmit side, vhost kthread calls the RAW socket’s ops sendmsg and it puts the packets into the KNI transmit FIFO. On the receive side, the kni kthread gets packets from the KNI receive FIFO, puts them into the queue of the raw socket, and wakes up the task in vhost kthread to begin receiving. All the packet copying, irrespective of whether it is on the transmit or receive side, happens in the context of vhost kthread. Every vhost-net device is exposed to a front end virtio device in the guest.
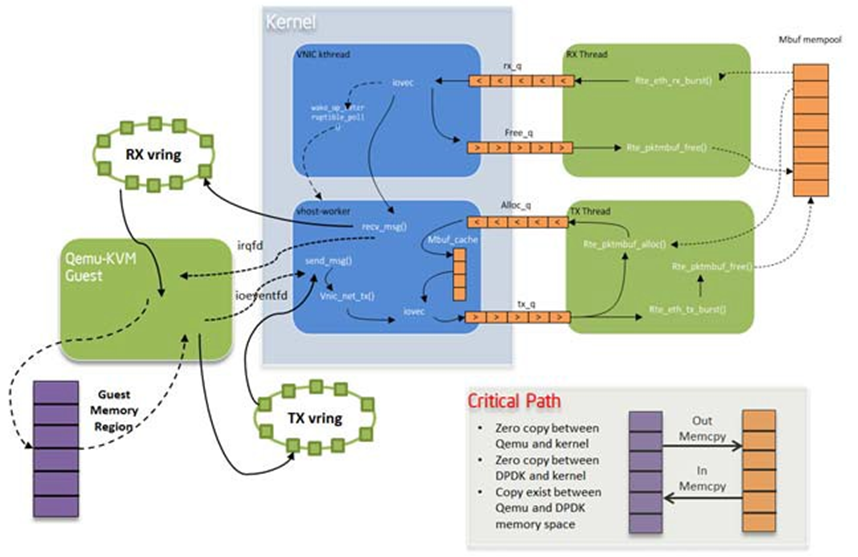
Fig. 18.4 KNI Traffic Flow
18.8.3. Sample Usage¶
Before starting to use KNI as the backend of vhost, the CONFIG_RTE_KNI_VHOST configuration option must be turned on. Otherwise, by default, KNI will not enable its backend support capability.
Of course, as a prerequisite, the vhost/vhost-net kernel CONFIG should be chosen before compiling the kernel.
Compile the DPDK and insert uio_pci_generic/igb_uio kernel modules as normal.
Insert the KNI kernel module:
insmod ./rte_kni.koIf using KNI in multi-thread mode, use the following command line:
insmod ./rte_kni.ko kthread_mode=multipleRunning the KNI sample application:
examples/kni/build/app/kni -c -0xf0 -n 4 -- -p 0x3 -P --config="(0,4,6),(1,5,7)"This command runs the kni sample application with two physical ports. Each port pins two forwarding cores (ingress/egress) in user space.
Assign a raw socket to vhost-net during qemu-kvm startup. The DPDK does not provide a script to do this since it is easy for the user to customize. The following shows the key steps to launch qemu-kvm with kni-vhost:
#!/bin/bash echo 1 > /sys/class/net/vEth0/sock_en fd=`cat /sys/class/net/vEth0/sock_fd` qemu-kvm \ -name vm1 -cpu host -m 2048 -smp 1 -hda /opt/vm-fc16.img \ -netdev tap,fd=$fd,id=hostnet1,vhost=on \ -device virti-net-pci,netdev=hostnet1,id=net1,bus=pci.0,addr=0x4
It is simple to enable raw socket using sysfs sock_en and get raw socket fd using sock_fd under the KNI device node.
Then, using the qemu-kvm command with the -netdev option to assign such raw socket fd as vhost’s backend.
Note
The key word tap must exist as qemu-kvm now only supports vhost with a tap backend, so here we cheat qemu-kvm by an existing fd.
18.8.4. Compatibility Configure Option¶
There is a CONFIG_RTE_KNI_VHOST_VNET_HDR_EN configuration option in DPDK configuration file. By default, it set to n, which means do not turn on the virtio net header, which is used to support additional features (such as, csum offload, vlan offload, generic-segmentation and so on), since the kni-vhost does not yet support those features.
Even if the option is turned on, kni-vhost will ignore the information that the header contains. When working with legacy virtio on the guest, it is better to turn off unsupported offload features using ethtool -K. Otherwise, there may be problems such as an incorrect L4 checksum error.